
本篇文章專注於探討 Log Structured Merge Tree(LSM Tree)的相關內容,我在這個主題上的理解尚有不足,在這邊拋磚引玉,非常歡迎讀者提出批評和指正。
場景與需求
不同的應用場景和讀寫需求對於資料存儲系統會有不同的要求。大致上,可以分為 「讀多寫少」和 「寫多讀少」 兩大類型。
針對這些不同的需求,存儲系統的設計會採取不同的策略和方案。例如,面臨 「讀多寫少」 的場景 , e.g.一個典型例子是MySQL中的InnoDB存儲引擎)。InnoDB基於 B+ Tree 的資料結構進行資料的組織和管理,這在關係型資料庫管理系統(RDBMS)中非常有效率。
無論是 CRUD 操作還是順序讀取,B+ Tree 可以提供優秀的效能,對於 Schema 設計妥當且 Query 的語法正確,基本上達到 O(logN)的速度。
前面把 InnoDB 捧上天,還是得說說 InnoDB 主要缺點,依賴於硬碟的隨機讀寫,而不是順序讀取,的兩個方向會在效能上造成了巨大的差異。
今天我們要討論的是「寫多讀少」使用場景,特別是LSM Tree(Log Structured Merge Tree)的內容。
許多著名的 NoSQL 資料庫引擎,如 LevelDB 、Cassandra 和 Hbase …等,都採用了基於 LSM Tree 的資料結構來實作。
LSM Tree 的資料結構將寫操作優化為順序寫入,從而提高了寫操作的效率,特別適合於「寫多讀少」的應用場景。
讀寫選擇
針對讀寫 Read/Write 操作的實作方式方案主要分為 「原地覆蓋」replace 和 「追加寫入」WAL兩種。這兩種方法在更新資料的操作過程中有著明顯的差異:
原地覆蓋(Replace)
當需要對一組 KV 資料進行更新時,必須先定位到原始資料的確切位置。 資料可能存儲在硬碟上的任何位置,這時候硬碟需要執行隨機讀取操作來查詢資料的所屬區塊。
例如:
Set(“a”, 1)
Set(“a”, 2)
Set(“b”, 1)
Set(“c”, 1)
原地覆蓋模式下,會記錄成(“a”, 2),(“b”, 1),(“c”, 1)三條記錄。要查詢最新的 “a” 的值,只需要直接查找 a 這一筆資料記錄即可。
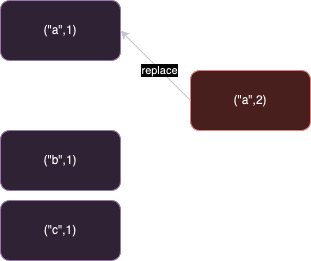
隨機讀寫操作比順序讀寫操作要慢得多,因為每次讀寫都可能需要硬碟頭移動到不同的位置,而這個移動過程會消耗額外的時間。特別是在執行大量隨機讀寫操作時,效能影響更為顯著。
追加寫入(Write-Ahead Log,WAL):
在追加寫入 (Write-Ahead Log,WAL) 模式下,Write 操作不需要區分是 插入/新增 (Insert/Create)還是更新(Update),
KV 的所有變化都直接追加到檔案的末尾。這種方法避免了硬碟查找資料原始位置所需的隨機讀取操作,以及將資料寫回這些位置所需的隨機寫入操作,從而在寫入效率上相較原地覆蓋(Replace)方案有明顯的提升。
在把 WAL 吹噓一番後,WAL 策略也有相對應的劣勢,同一個 Key 可能會產生多份冗餘資料。除了最新的記錄外,之前的資料記錄實際上都是不再需要的,這會造成空間的浪費。
例如:
Set(“a”, 1)
Set(“a”, 2)
Set(“b”, 1)
Set(“c”, 1)
WAL 模式下,會記錄成(“a”, 1),(“a”, 2),(“b”, 1),(“c”, 1)四條記錄。要查詢最新的 “a” 的值,需要從檔案末尾開始向前查找,直到找到第一筆符合條件的 key為止也就是 a 。
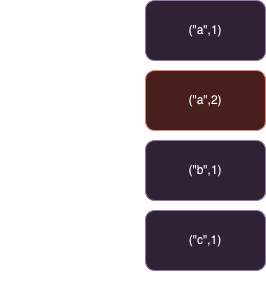
採用追加寫入策略的讀操作效能較差。需要根據 key 查詢資料時,都需要從檔案末尾開始向前逐步追溯,直到找到第一筆符合條件的 key 為止,在這種查詢模式之下查詢的時間會隨著資料量膨脹而增長,對於效能要求較高的應用來說是比較難以接受的。
LSM Tree
將從零開始,與讀者一同探討 Log Structured Merge Tree(LSM tree)的設計理念。
首先,我們的目標是盡可能最佳化 「寫多讀少」的應用場景,其中包括兩個核心需求:
- 提升 Write 操作的效率作為首要目標,因為 Write 操作是我們面對的主要使用場景。
- Read 操作的效率雖可稍作妥協,但仍需保持在可接受的範圍內。
基於這些考慮,「WAL」策略成為了我們的首選。接下來的問題是,在保留 WAL 所帶來的優勢的同時,如何盡可能地緩解 Read 操作效率及空間利用率的負面影響。
WAL 的挑戰
-
資料冗餘和空間浪費:由於資料是簡單地追加到文件末尾,同一組鍵值對可能存在多份記錄,導致空間浪費。
在資料寫入或更新作業中,採用 WAL 寫入方式時,通常會忽略 Key 先前的狀態,直接進行追加。這種方法簡單粗暴。但不可避免導致了一個 Key 紀錄多次的狀況。
除了最後一筆記錄外,先前的多個舊資料都屬於無用的冗餘資料。在極端情況下,沒有對 WAL 寫入策略進行任何最佳化,只需一組 KV 資料,就可以透過無限次的更新操作就能填滿整個硬碟空間。
-
讀取效率低下:查詢一個 KV 需要從檔案末尾開始反向查詢,時間複雜度為O(N)這對於效率要求是不可接受的。
例如:
Set(“a”, 1)
Set(“b”, 1)
Set(“c”, 1)
Set(“a”, 2)
要查詢 b 的話需要從末尾開始向前查找,直到找到第一筆符合條件的為止。
為了克服這些挑戰,我們將按照以下步驟進行優化:
資料合併(Data Merge)
在資料寫入或更新作業中,採用 WAL 寫入方式時,通常會忽略 Key 先前的狀態,直接進行追加。這種方法簡單粗暴。但不可避免導致了一個 Key 紀錄多次的狀況。
除了最後一筆記錄外,先前的多個舊資料都屬於無用的冗餘資料。在極端情況下,沒有對 WAL 寫入策略進行任何最佳化,只需一組 KV 資料,就可以透過無限次的更新操作就能填滿整個硬碟空間。
鑑於可能存在多個冗餘資料,我們可以考慮採用壓縮合併(Merge)的方法來解決這個問題。
這意味著除了主要的讀寫流程外,還要使用一個專門負責壓縮與合併的 非同步元件 。這個 非同步元件 將 持續監控 重複的 KV 資料,並進行合併,只保留最新的記錄,從而消除先前的無用資料。
然而,採取這種方法後會帶來新的問題。因為寫入操作和壓縮操作針對相同檔案時需要互斥進行,否則可能會導致嚴重的並發問題。
一旦我們採取了互斥操作,即在檔案壓縮合併期間,寫入操作就會被阻塞。這樣就會嚴重影響系統的效能和使用體驗
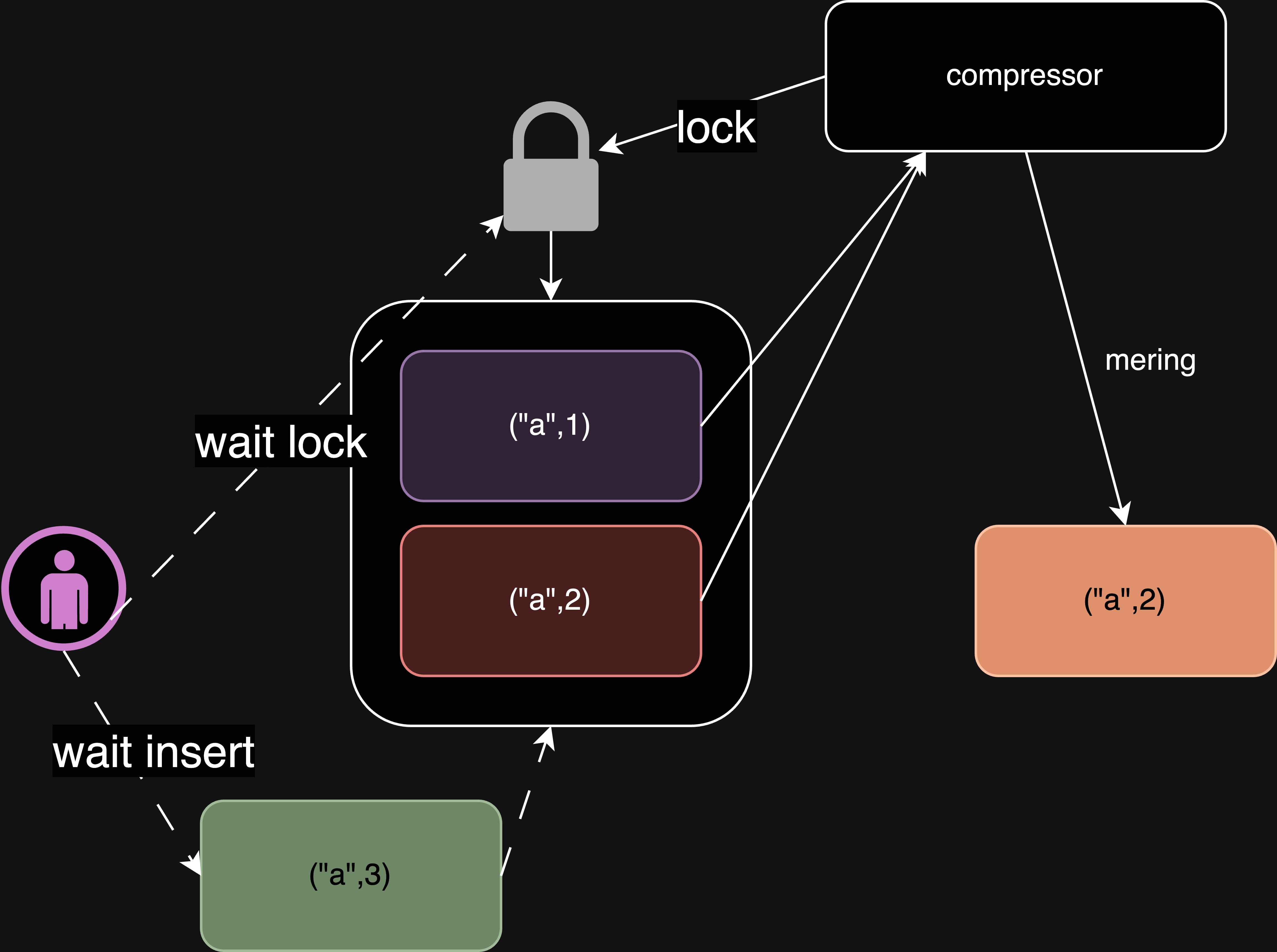
文件分塊(File Segmentation)
為了解決 Write 和 Merge 操作的互斥問題,我們可以將大文件(File) 拆分成多個小文件(File Segmentation)。
並將 Write 操作限制在 最新的 (File Segmentation)中,異步 Merge 動作只能對 舊的(File Segmentation)進行操作,從而解耦 Write 與 Merge 兩個流程。
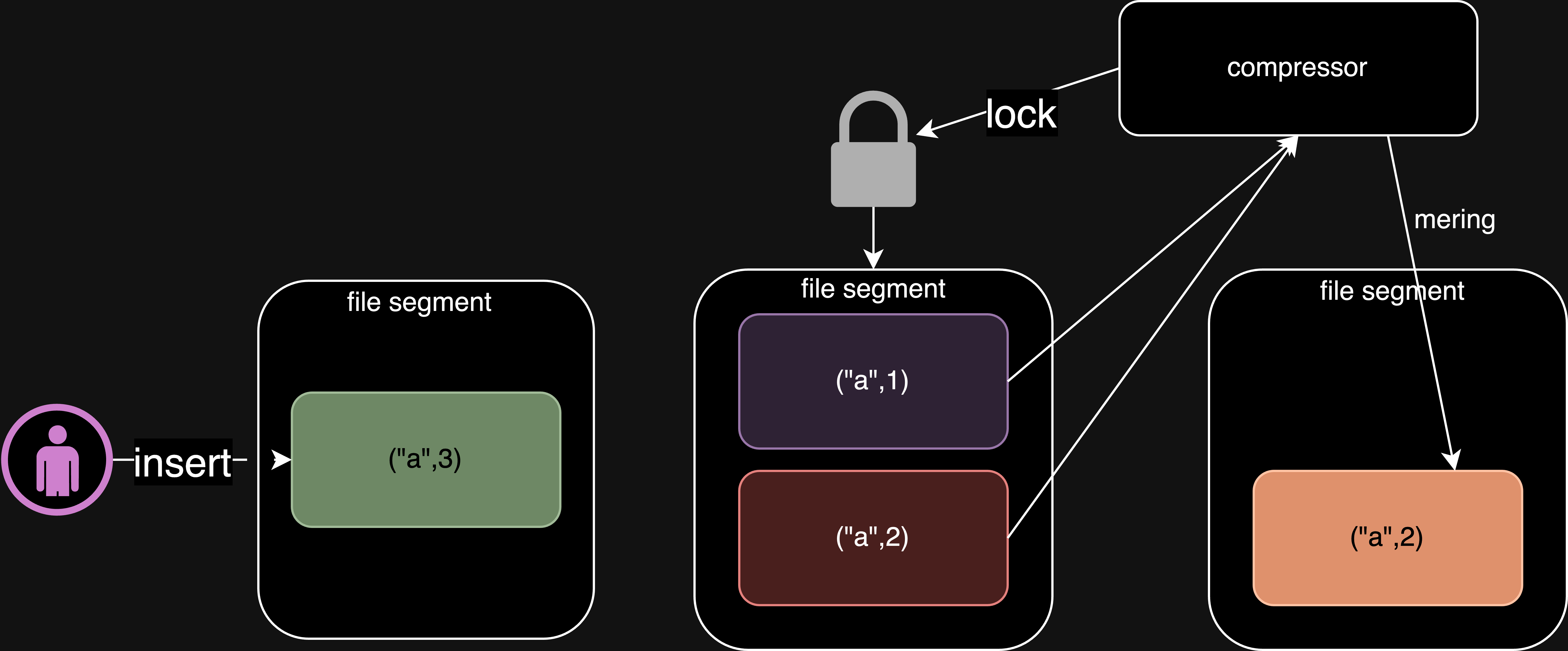
資料有序儲存(Sequential Write)
接下來我們聊聊 WAL 存在的另一個問題:效能很差的 Read。
採用追加寫入策略的
讀操作效能較差。需要根據 key 查詢資料時,都需要從檔案末尾開始向前逐步追溯,直到找到第一筆符合條件的 key 為止,在這種查詢模式之下查詢的時間會隨著資料量膨脹而增長,對於效能要求較高的應用來說是比較難以接受的。
例如:
Set(“a”, 1)
Set(“a”, 2)
Set(“b”, 1)
Set(“c”, 1)
WAL 模式下,會記錄成(“a”, 1),(“a”, 2),(“b”, 1),(“c”, 1)四條記錄。要查詢最新的 “a” 的值,需要從檔案末尾開始向前查找,直到找到第一筆符合條件的 key為止也就是 a 。
WAL 的讀效能一直是其一個較大的缺點。目前,WAL 的 Read 取操作需要對全部的資料進行逆序的逐一查詢,直到找到滿足條件的第一筆 KV ,這種方式的時間複雜度為 O(n)。
優化 Read 效能的方案
為了優化 WAL 的 Read 效能,我們可以對 kv 對的存儲組織結構進行改進。一種可行的方案是,在組織每個 File Segment 內的資料時,先根據 Key 進行資料排序。
這樣一來,在後續的查詢環節,就可以使用二分查詢的方式來快速定位目標資料。二分查詢的時間複雜度為 O(log n),相比於線性遍歷有明顯的優勢。
我們討論了 WAL 的讀效能問題,並提出了一個基於 k 排序的優化方案。然而,該方案會對 WAL 的基礎設定造成一定的影響。
WAL 的基礎設定之一是,kv 資料在 file segment 中的存放順序是按照寫入時間來的。這意味著,WAL 的寫入操作是 append-only 的,不能隨意修改 kv 資料的存放順序。
而基於 k 排序的優化方案要求,kv 資料必須按照 k 進行排序。這就與 WAL 的基礎設定產生了矛盾。
記憶體儲存 memtable
我們討論了 WAL 的讀效能問題,並提出了一個基於 k 排序的優化方案。然而,該方案會對 WAL 的基礎設定造成一定的影響。
WAL 的基礎設定之一是,kv 資料在 file segment 中的存放順序是按照寫入時間來的。這意味著,WAL 的寫入操作是 append-only 的,不能隨意修改 kv 資料的存放順序。
而基於 k 排序的優化方案要求,kv 資料必須按照 k 進行排序。這就與 WAL 的基礎設定產生了矛盾。
為了解決上述中與 WAL 互相矛盾的問題,我們在硬碟檔案 file segment 的基礎之上,額外引入在記憶體中維護的 memtable 結構。memtable 來作為 WAL 的寫入緩衝區。
memtable 在記憶體中維護一個有序的 kv 資料結構,使用者寫入操作都會先寫入到 memtable 中。當 memtable 中的資料量達到一定閾值後,再將其溢位 flush 到硬碟,成為 file segment。
首先確定以下幾個個事項:
- memtable 存在記憶體中
- memtable 本身基於 k 有序的特性,可以透過二分查詢加速查詢
- memtable 中的 write 操作統一採用就地覆蓋(Replace)的方式,不會產生冗餘資料
- memtable 是的對外唯一 Write 操作接口
- memtable 資料量達到閾值後溢位 flush 到硬碟,成為 file segment
- memtable 中的 write 操作統一採用就地覆蓋(Replace)的方式,不會產生冗餘資料
由於 memtable 資料存在於記憶體中,在查詢的速度比硬碟快好幾十倍,因此 write 操作可以採用 replace 的方式,直接覆蓋原始的舊資料。如此一來,memtable 中的資料不會產生冗餘,也不會浪費空間。--
加入 memtable 之後,也引發出了三個新的問題:
- memtable 本身基於 k 有序的特性,要採用什麼樣的資料結構來實現有序的 kv 資料結構。
- 儲存於記憶體中有著易失性,需要考慮資料遺失的風險。
- memtable 資料量達到閾值後溢位 flush 到硬碟,成為 file segment,這個行為涉及到硬碟 IO 的操作,同時間只能有一個 memtable 溢位到硬碟。
有序的 kv 資料結構
memtable 本身基於 k 有序的特性,要採用什麼樣的資料結構來實現有序的 kv 資料結構,從而確保所有的 Read 操作和 Write 操作都能在 O(log N) 的時間複雜度內。
常見的資料結構包括: AVL Tree、Red-Black Tree、Skip List 等。這些資料結構都可以實現有序的 kv 資料結構,但各自有著不同的特點。
- AVL Tree
AVL Tree 是一種自平衡二元樹,其高度為 O(log n),n 為樹中的節點數。AVL Tree 的插入、刪除和查詢操作的時間複雜度均為 O(log n)。
AVL Tree 適合
讀取操作遠多於寫入操作的場景,因為每次插入或刪除操作後可能需要通過旋轉來重新平衡樹,這個操作成本相對昂貴。
- Red-Black Tree
Red-Black Tree 是一種自平衡二元樹,其高度為 O(log n),n 為樹中的節點數。Red-Black Tree 的插入、刪除和查詢操作的時間複雜度均為 O(log n)。
Red-Black Tree 相較於 AVL Tree 在平衡條件上較為寬鬆,因此在插入和刪除操作時重新平衡的成本通常低於 Red-Black Tree,所以
Red-Black Tree寫入操作較多的場景下表現比 AVL Tree更好。
- Skip List
Skip List 是一種機率形的資料結構,插入、刪除和查詢操作的時間複雜度均為 O(log n)。Skip List 的空間複雜度為 O(n log n)。
實作相對AVL Tree、Red-Black Tree來說簡單,並且插入和刪除操作不需要像其他兩種資料資料結構進行複雜的重平衡操作。因為 Skop List 相較其他兩種資料結構來說比較容易支持鎖細化(Lock-Free)操作。
| 資料結構 | 優點 | 缺點 |
|---|---|---|
| AVL Tree | 插入、刪除和查詢操作的時間複雜度均為 O(log n) | 需要額外的空間來維護平衡性 |
| Red-Black Tree | 插入、刪除和查詢操作的時間複雜度均為 O(log n) | 比 AVL Tree 更複雜 |
| Skip List | 插入、刪除和查詢操作的時間複雜度均為 O(log n) | 空間複雜度為 O(n log n) |
在實際應用中,可以根據具體的需求來選擇合適的資料結構。本篇文章將以 Skip List 作為例子進行介紹。
資料丟失的風險
在 memtable 中,資料是採用就地覆蓋(Replace)的方式進行儲存的。這種方式雖然效率較高,但卻存在一個問題:如果發生宕機,記憶體中的資料就會丟失,
如下圖所示 記憶體中的 active/readonly 沒辦法 get/flush 資料。
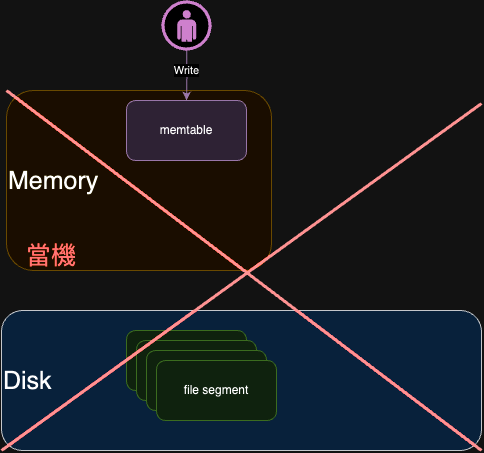
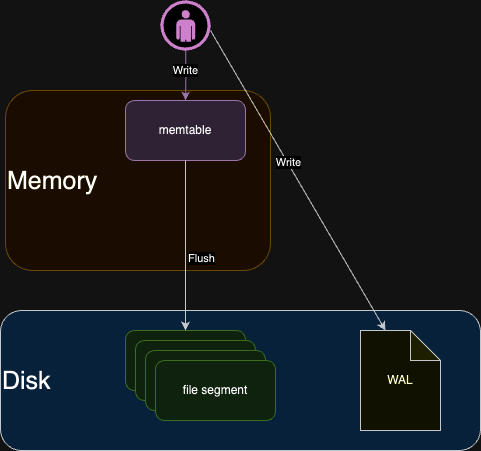
根據上述問題,可以採用 WAL 技術。在使用 WAL 技術之前,我們需要先在硬碟上建立一個預寫日誌(write-ahead log)。在對 memtable
進行更新之前,我們會先將更新操作記錄到預寫日誌中。這樣一來,即使發生宕機,我們也可以通過重放預寫日誌(redo log)來恢復
memtable 中的資料。
另外 WAL 中的寫入操作是直接寫在檔案的最後一行 (End Of Line, EOF),屬於硬碟順序 IO。這樣操作的效能較高。
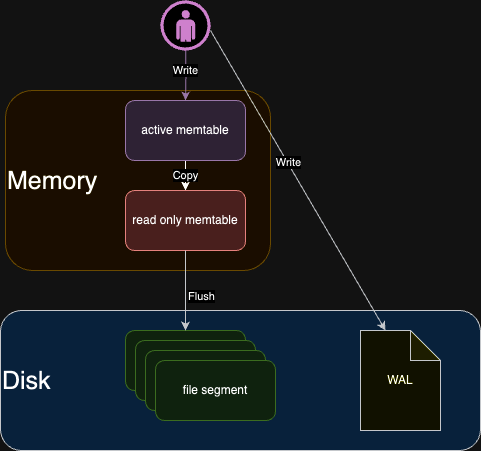
memtable 溢位到硬碟
memtable 資料量達到閾值後溢位到硬碟,成為 file segment,這個行為涉及到硬碟 IO 的操作,同時間只能有一個 memtable 溢位到硬碟。
為了解決這一問題,當 memtable 需要溢位時,我們可以將其一分為二:
- 將已有的舊資料歸屬到 readonly memtable 部分,成為一個只讀的資料結構,專注於執行將其溢位 flush 到硬碟的流程。
- 建立一個全新空白的 active memtable,作為寫操作的新入口。
資料分層 (File Segmentation Level)
在文件分塊(File Segmentation)小結中,提到了將大型文件拆分成多個小文件(File Segmentation)的策略,並將寫入操作限制於最新的文件(File Segmentation)中
而將異步合併操作只針對舊的文件段進行。這種做法有效地解耦了寫入和合併流程,提高了系統的整體效能和靈活性。
在這一策略中,文件段的概念帶來了以下幾點核心優勢:
-
減少資料冗餘:由於在 Memtable 階段採用 replace 策略,每個 file segment 內部不會存在重複的 kv 資料
- Memtable 確保了 file segment 存儲的效率和空間利用率。
-
資料有序性:Memtable 的資料是有序的,因此從 Memtable flush 到硬碟生成的 file segment 內部的鍵值對資料也保持有序
- Memtable 確保了 file segment 的資料順序。
當不同的 File Segmentation 需要進行資料整理,例如去重複與全域排序時。這樣的操作對於整個資料庫系統來說是一個非常耗時的操作。
File Segmentation 只能保證自己的資料擁有 Memtable 的特性。
跨 File Segmentation 就無法保證資料的有序與去重複特性。
為進一步優化這一結構,我們引入了硬碟文件分層的概念,將資料分層分為多個層級,從level 0到 level k,其中每一層的 File Segmentation 容量按一定比例遞增。
這一種層次結構支援資料的有序流動(由 level 低流向 level 高):
level 0
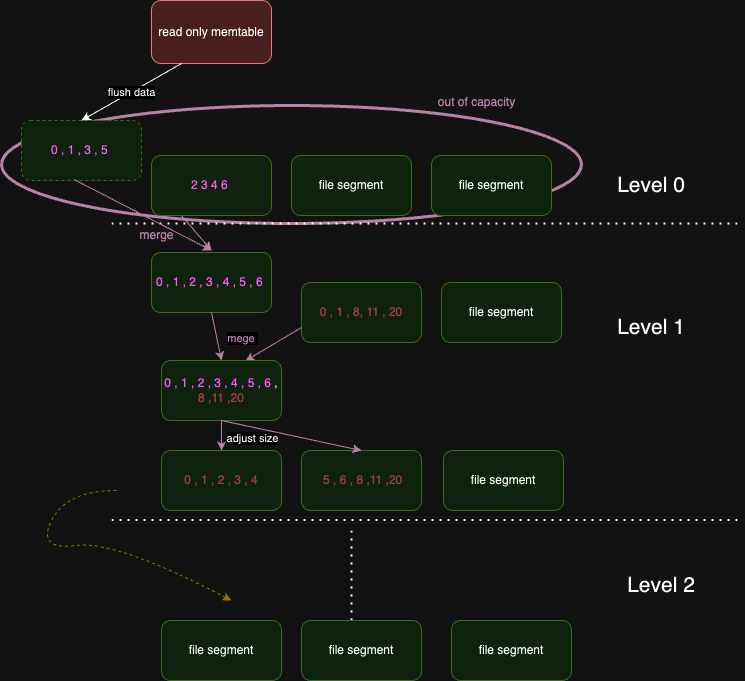
level 0 是一個特殊層次:由於資料直接來自 Memtable , level 0 可能包含一定程度的資料冗餘,並且不保證在這一層有序排列。
-
以下圖為例 Level 0 有 3 個 file Segment,每個 File Segment 都是 Memtable 溢位 flush 到硬碟的結果,因此 file Segment 內部的資料是有序的。
-
這一次 Memtable 溢位 flush 到硬碟產生 file segment ,達到了閾值。 Level 0 的 file segment 會進行合併操作,合併後的新 file segment 會被插入到 level 1 中。
-
level 1 以後的層次,每一層的 File Segment 都是由上一層的 File Segment 合併而來,因此每一層的 File Segment 都是有序的。
-
這樣的設計保證了從 level 1 開始的每一層內部資料無重複且全局有序。
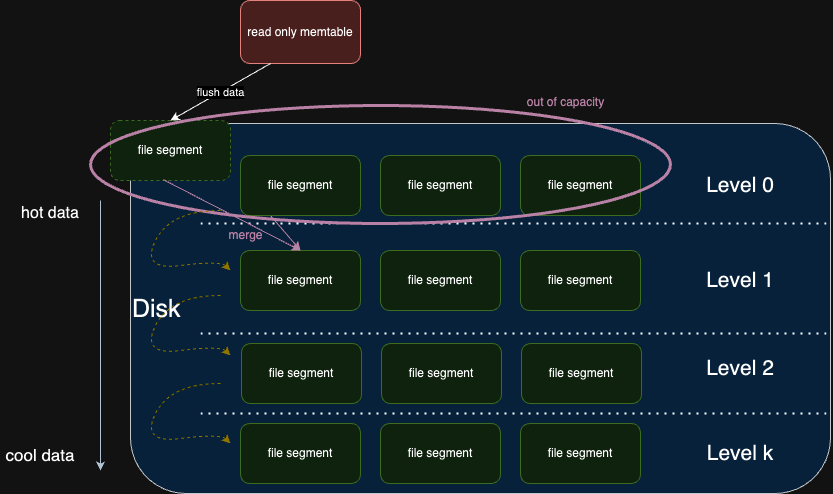
level 1 ~k
以下圖來說明 level 0 ~ level 1 的合併過程。用同樣的原理可以推至 level 1 ~ level k 的合併過程。
- read-only memtable 會被 flush 到硬碟,成為 level 0 的 file segment。
- level 0 的 file segment 達到閥值後,會進行合併操作,合併後的新 file segment 會被插入到 level 1 中。
為簡化圖片 kv 資料僅以 k 表示。
0,1,3,5 與 2,3,4,6 合併後變成 0,1,2,3,4,5,6 - level 1 的 file segment 與 level 0 傳遞下來的 file segment 進行合併
0,1,2,3,4,5,6 與 0,1,8,11,20 合併
合併的過程中會與上層傳遞下來的資料進行去重複與全域排序。
0,1,2,3,4,5,6 與
0,1,8,11,20 合併後變成
0,1,2,3,4,5,6,8,11,20
有重複的 k 的話會採用上層傳遞下來的 k ,因為上層傳遞下來的值較新。 - 根據 level 1 的規範,合併後的 file segment 可以切分成 n 個 file segment ,通常 file segment 大小會是上一層的 K倍。
只是舉例:
0,1,2,3,4,5,6,8,11,20 切分成 兩個 file segment
0,1,2,3,4 與 5,6,8,11,20 - 以此類推,層層推進,直到 level k。
越往下層的資料越冷,越上層的資料越熱。試想一下,如果我們要查詢一個資料,我們會先從 level 0 開始查詢,如果找到了就不用再往下查詢了。這樣就大大提高了查詢效率。
總結
在本文中,我們從零開始,與讀者一同探討寫多讀少 的場景下如何設計一個高效率的資料結構。
第一部分
我們討論到 Replace 和 WAL 兩種寫入策略的優缺點,並提出了一個基於 WAL 的設計方案。
接著,我們討論了 WAL 的資料冗余和讀取效能低下的問題
對於資料冗余,我們提出了一個 Merge 的解決方案,通過對重複的 KV 資料進行合併,消除了冗余資料。
這樣的方法雖然解決了資料冗余的問題,但卻帶來了新的問題:寫入操作和合併操作之間的互斥問題。
為此,我們提出了一個文件分塊的解決方案,將大文件拆分成多個小文件,並將寫入操作限制在最新的文件中,異步合併操作只針對舊的文件進行操作,從而解耦了寫入和合併流程。
對於讀取效能低下,我們提出了一個基於 Sequential Write 的解決方案,將 KV 資料按照 Key 有序的方式存儲,並使用二分查詢的方式來快速定位目標資料。
這樣的方法雖然提高了讀取效能,但卻與 WAL 的基礎設定產生了矛盾。為此,我們引入了一個
Memtable的概念,將 KV 資料先寫入到 Memtable 中,再溢位 flush 到硬碟,從而解決了這一問題。
第二部分
我們討論到 Memtable 要如何實現有序的 KV 資料結構,並且資料儲存於記憶體當中有著易失性的問題。提出了一個 skip list 的解決方案,並且引入了 WAL 技術來解決資料丟失的風險。
對於 skip list 的實現,我們討論了 AVL Tree、Red-Black Tree 和 Skip List 三種資料結構的優缺點,並選擇了 Skip List 作為實現方案。
skip list 相較於 AVL Tree 和 Red-Black Tree 來說,實作相對簡單,並且插入和刪除操作不需要像其他兩種資料結構進行複雜的重平衡操作。因此,skip list 更適合用於 Memtable 的實現。
對於資料丟失的風險,我們引入了 WAL 技術,將 Memtable 的更新操作記錄到預寫日誌中,從而保證了資料的持久性。
WAL 技術也可以說是 undo log 的概念,將 Memtable 的更新操作記錄到預寫日誌中,在發生斷電等異常情況時,可以通過重放預寫日誌來恢復 Memtable 中的資料。
有了 Memtable 之後,我們討論到 Memtable 溢位到硬碟的問題
當 Memtable 需要溢位時,我們可以將其一分為二:將已有的舊資料歸屬到 readonly memtable 部分,成為一個只讀的資料結構,專注於執行將其溢位 flush 到硬碟的流程。建立一個全新空白的 active memtable,作為寫操作的新入口。
溢位到硬碟的資料會成為 file segment,file segment 有著 memtable 的特性,也就是
- 資料無重複
- 資料有序
第三部分
我們討論到當 memtable 溢位到硬碟後,會形成 file segment,過多個 file segment 要如何高效的管理儲存空間與提高讀取效能。
我們提出了一個 資料分層 的概念,將資料分層分為多個層級,從 level 0 到 level k。 透過多層次結構支援資料的有序流動(由 level 低流向 level 高):
對於 level 0,用簡單的範例來說明其特性。
level 0 是一個特殊層次:由於資料直接來自 Memtable , level 0 可能包含一定程度的資料冗餘,並且不保證在這一層有序排列。
對於 level 0 資料,要如何沈澱到 level 1,我們提出了一個 合併 的概念,並用簡單的範例說明。
level 0 的 file segment 達到閥值後,會進行合併操作,合併後的新 file segment 會被插入到 level 1 中。
level 1 以後的層次,每一層的 File Segment 都是由上一層的 File Segment 合併而來,因此每一層的 File Segment 都是有序的。
寫入流程
TODO
讀取流程
TODO